
User Tools
Sidebar
This wiki is not maintained! Do not use this when setting up AuScope experiments!
Handover notes
Please use this page to write up any notes on anything that needs to be passed on to the next observer or should go into the end of experiment message.
Notes should be placed below the horizontal line as a new blog entry.
Continuing problems should be copied to the Current Issues page.
**Template for Handover notes:**
Be sure to add any specific notes about the experiment if required, for example “Special back end configuration for x reason”. Put as much detail as you can - the more the better.
====== Experiment Name ====== **Hobart 12m** Disk VSN: abc-123 | Data volume at beginning: 2.34 GB * 1300UT a comment from me (user) **Katherine 12m** Disk VSN: | Data volume at beginning: GB * **Yarragadee 12m** Disk VSN: | Data volume at beginning: GB * 1300UT Experiment started okay (JMc).
Format for entering a comment It is important to stick to this formula - there is a good reason we need this information, so please include it!
Time stamp in UT * Comment * (Your Name)
For Example:
20:00UT: Wind stows, Missed scans 012-3456 to 012-3457 (Jim)
20:50UT: Mark5 lost connection, had to restart Mark5 and reconfigure DBBC, called Jamie on call to fix, missed scans 012-3456 to 012-4567 (Jim)
Again - as much detail as you can. It is important to remember that these notes will be sent to the correlator, so please make sure they make sense to others.
crds85
Hobart 26m:
Disk VSN: HOB+1006
Data volume at beginning: 0 GB
- 18:30 UT Experiment started OK. (Bryn)
- 15:30 UT Disc pos ~90 GB behind with no explanation and no previous tracking of the problem. (Ellen)
Hobart 12m:
Disk VSN: HOB+0088 then USN-0102
Data volume at beginning: HOB+0088 – 5065 GB, USN-0102 – 0 GB
- 18:30 UT Experiment started OK. (Bryn)
- 00:56:30 (272) UT changed modules from HOB-0088 with 610.6 of CRDS85 already recorded to USN-0102 with 0 GB at start, first scan 272-0058 (Warren)
- 0433UT Brett stopped telescope for maintenance (JS)
- 0533UT Resumption of schedule after maintenance, first scan at 0540UT (JS)
Yarragadee 12m:
Disk VSN: HOB+1000
Data volume at beginning: 0 GB
- 18:30 UT Experiment started OK (Bryn)
Katherine 12m:
Disk VSN: USN-0085
Data volume at beginning: 0 GB
* 05:52 UT first scan after DBBC fix 272-0552 (Warren) * All X-band (channels 01-08) tsys measurements are overflowing. (Ellen)
R1759
Hobart 12m
Start of experiment, 6630.0GB recorded to HOB+0088
- Experiment started okay (Lucas)
Yarragadee 12m
Start of experiment, 0.000GB recorded to BKG-0064
- Experiment started okay (Lucas)
- 1247UT pcfs not responding (Jonathan)
- IP switch not responding - possible power outage?
- 13:10 UT Reset VPN, everything OK now. (Bryn)
HOB005
Hobart 12m
AUST/normal setup procedures followed but SNP file wasn't/isn't downloaded with drudge. No .sum file either. Only noticed when attempted to start schedule got “ERROR bo -105 Error opening schedule file FMP ? FFF”. Turns out proc file had extra ifd=(blank) which, when deleted, allowed a successful drudge.
Jamie fixed all the problems.
Disk_module HOB+0.0088.
First good scan, 269-1909 at 19:09UT disk_pos=1542.798 GBs
Hobart 26m
As per notes on here: (http://auscope.phys.utas.edu.au/opswiki/doku.php?id=observing:hohb) the mk5 was swapped over. And schedule started. Initially got nominal response from mk5=dot? So started schedule. Got error “ERROR tc -302 TPICD not set-up: no detectors selected”. After observer and on-call person attempted to fix, status went from bad to worse and errors concerning wrong mode selected in equip.ctl file started. And disk_record=off no longer worked as “Error m5 -900: Can't record with Mark-5B DOM”.
Started restarting entire setup and Jamie took over and fixed most problems apart from TIPCD error which he said he will work on an update for equip.ctl file.
Disk_module HOB+1010 First 'good' scan 269-1930 at 19:30 UT disk_pos=2602.831 GBs
R4758
Hobart 12m:
Disk VSN: HOB+0088
Data volume at beginning: 7.112 GB
- 18:30 UT Experiment started OK. (Bryn)
Katherine 12m:
Disk VSN: HOB+0059
Data volume at beginning: 4598.450 GB
- 18:30 UT Issues with DBBC in previous experiment, waiting on Jamie or Jim to fix for experiment to start (Bryn)
Yarragadee 12m:
Disk VSN: USN-0115
Data volume at beginning: 0 GB
- 18:30 UT Experiment started OK - Telescope slewing during first scan. First good scan 266-1834 (Bryn)
aug029
General Notes*
- 16:45 UT Kept losing network access while trying to fix Ke problems (live webpages would become unresponsive). Did not impact hb or yg erc for some reason. (Bryn)
Hobart 12m:
Disk VSN: HOB+0074
Data volume at beginning: 2694.897 GB
- 18:00 UT Experiment started OK. Scan 265-1800, source 0454-234. (AK)
Katherine 12m:
Disk VSN: HOB+0059
Data volume at beginning: 0 GB
- 18:07 UT experiment started late. Module had no vsn and internal light at ke didn't work, needed confirmation from on call person to give a place holder name. (AK)
- 16:16 UT First scan 265-1816. Source 2255-282. (AK)
- 16:01 UT DBBC pps_delay1 = 2048031248. ALARM: Delay through DBBC has changed. Monitor for stability and reset DBBC if it drifts. DBBC delay returned to regular levels after this one alarm, however, the autocorrelation spectra are awful. Reconfiguring DBBC. Missed scans 266-1600 onwards (Bryn)
- 16:30 UT Reconfiguring DBBC did nothing autocorrelations still terrible (see attached), trying reboot of DBBC machine. (Bryn)
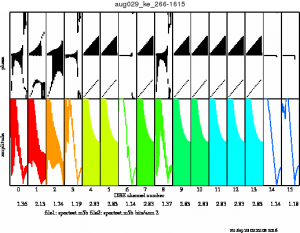
- 18:00 UT Was unable to fix issues with DBBC, all scans from 266-1600 onwards bad.

Yarragadee 12m:
Disk VSN: HOB+0100
Data volume at beginning: 674.261 GB
- 18:00 UT Experiment started OK. Scan 265-1800, source 0454-234. (AK)
Hobart 26m:
Disk VSN: HOB+1006
Data volume at beginning: 0 GB
- 18:00 UT Lots of following errors
- ERROR ch -369 IF3 lo is unlocked.
- ERROR ch -371 IF3 alarm is on
- ERROR ch -371 IF3 alarm is on
- ERROR ch -309 v3 alarm is on
- ERROR ch -309 v6 alarm is on
- ERROR ch -309 v7 alarm is on
- ERROR ch -309 vb alarm is on
- ERROR ch -309 vc alarm is on
- 1900 UT Jamie had a look and tried to fix it. He wasn't convinced that he had fixed the problem but the error messages disappeared. Brett has suggested power cycling the VC rack. Holding off on going to MT pleasant as there are currently no errors.
- 20:11 UT disk_pos is 60 GB behind already. (AK)
- 21:08 UT It appears the telescope didnt follow the schedule and stowed for some reason. First valid scan was 265-2108.
- 00:05 UT Tried manually cycling power to VC rack, no luck - errors still persist. Jim L stowed telescope. (Bryn)
aov011
Mk5=mode? is “ 0x55555555 : 4 : 2 ; ” should be 0xffffffff according to wiki and prc file?
Hobart 12m:
Disk VSN: HOB+0120
Data volume at beginning: 23293.563 GB
- Experiment Started okay (Liz)
- 11:15 UT autocorrelation plots not updating, assume due to rapid data transfers in progress (Warren)
Katherine 12m:
Disk VSN: BKG+0141
Data volume at beginning: 6.090 GB
- 17:30 Experiment started okay (Liz)
- 17:35 UT Alarm “mark 5 reports sync error. Check clock stability.” which developed into “dbbcn:error connect():dbbc device connection open timed-out”. Had to halt schedule, power cycle the DBBC and fmset to fix. First good scan 264-1815 (Liz)
- 18:25 UT Autocorrelations showing distinct but small delta-like peaks along the whole image. Better than before DBBC cycled so just leaving and watching for now. (Liz)
- 20:44 UT and 21:19UT “WARNING: error an -103 pointing computer tracking errors are too large. WARNING: error qo -301 warning: onsource status is slewing! ALARM: error m5 -900 not while recording or playing” Acknowledged alarm, seems not to have affected anything (Liz).
2016.264.20:43:04 WARNING: error m5 -906 mark5 return code 6: inconsistent or conflicting request
* 00:30 UT system temperature readings overflowing constantly (Warren) * 05:56 UT failed to get on source before next source commanded (Warren)
Yarragadee 12m:
Disk VSN: HOB+0100
- 17:52UT Experiment started late as slow changing modules since yg operator didn't know we needed a new module after he took the r1 module out… First scan: 264-1752 (Liz)